Comparative Cell-Cell Communication with LIANA+ and CrossTalkeR#
Background#
CrossTalkeR (Nagai et al., 2021) represents cell-cell communication as a directed graph: nodes are cell types and edges are the ligand-receptor signals sent between them. By scoring each node’s importance in this graph (e.g. via PageRank) and comparing those scores between two conditions, it highlights the cell types whose communication patterns change the most — i.e. the candidate condition-driving cell types and their ligand-receptor interactions.
pyCrossTalkeR is the Python implementation of CrossTalkeR. In addition to the graph rankings, it tests which interactions differ significantly between conditions using two complementary features: the number of interactions (proportion / Fisher test) and their strength (expression / Mann-Whitney test).
In this notebook we take ligand-receptor scores inferred per condition with liana, hand them to pyCrossTalkeR, and walk through the comparative graph, ranking, and statistical views to read out how IFN-β stimulation reshapes PBMC communication.
Load Packages#
Install required packages via pip with the following command:
pip install pycrosstalker
import pandas as pd
import scanpy as sc
import plotnine as p9
import liana as li
import warnings
warnings.filterwarnings('ignore')
from collections import defaultdict
from pycrosstalker import tools as cttl
from pycrosstalker import plots as ctpl
%matplotlib inline
from scipy.stats import gmean
import os
sc.logging.print_header()
| Package | Version |
|---|---|
| pandas | 2.2.2 |
| scanpy | 1.11.4 |
| plotnine | 0.15.0 |
| liana | 1.7.1 (1.7.3) |
| pycrosstalker | 2.1.6 |
| scipy | 1.15.3 |
| Component | Info |
| Python | 3.13.7 | packaged by conda-forge | (main, Sep 3 2025, 14:24:46) [Clang 19.1.7 ] |
| OS | macOS-15.7.7-arm64-arm-64bit-Mach-O |
| CPU | 8 logical CPU cores, arm |
| GPU | No GPU found |
| Updated | 2026-06-29 11:49 |
Dependencies
| Dependency | Version |
|---|---|
| setuptools | 80.9.0 |
| llvmlite | 0.45.0 |
| pyparsing | 3.2.5 |
| Jinja2 | 3.1.6 |
| igraph | 1.0.0 |
| xarray | 2025.12.0 |
| numpy | 2.3.3 |
| leidenalg | 0.11.0 |
| PyYAML | 6.0.3 |
| pycparser | 2.23 |
| comm | 0.2.3 |
| cloudpickle | 3.1.2 |
| urllib3 | 2.5.0 |
| dask | 2024.11.2 |
| Pygments | 2.19.2 |
| matplotlib-inline | 0.1.7 |
| cffi | 2.0.0 |
| texttable | 1.7.0 |
| natsort | 8.4.0 |
| jupyter_core | 5.8.1 |
| certifi | 2025.8.3 (2025.08.03) |
| executing | 2.2.1 |
| plotly | 6.8.0 |
| threadpoolctl | 3.6.0 |
| pillow | 11.3.0 |
| kiwisolver | 1.4.9 |
| sankeyflow | 0.4.1 |
| anndata | 0.12.2 |
| mudata | 0.3.2 |
| joblib | 1.5.2 |
| packaging | 25.0 |
| h5py | 3.14.0 |
| pytz | 2025.2 |
| decorator | 5.2.1 |
| parso | 0.8.5 |
| appnope | 0.1.4 |
| legacy-api-wrap | 1.4.1 |
| python-dateutil | 2.9.0.post0 |
| stack_data | 0.6.3 |
| adjustText | 1.3.0 |
| docrep | 0.3.2 |
| platformdirs | 4.4.0 |
| attrs | 25.4.0 |
| requests | 2.32.5 |
| seaborn | 0.13.2 |
| tornado | 6.5.2 |
| jupyter_client | 8.6.3 |
| idna | 3.10 |
| ipython | 9.6.0 |
| statsmodels | 0.14.5 |
| pure_eval | 0.2.3 |
| tqdm | 4.67.1 |
| pyzmq | 27.1.0 |
| MarkupSafe | 3.0.3 |
| donfig | 0.8.1.post1 |
| cycler | 0.12.1 |
| session-info2 | 0.2.2 |
| traitlets | 5.14.3 |
| networkx | 3.5 |
| asttokens | 3.0.0 |
| gprofiler-official | 1.0.0 |
| numcodecs | 0.16.3 |
| numba | 0.62.0 |
| jedi | 0.19.2 |
| mizani | 0.14.2 |
| zarr | 3.1.3 |
| ipykernel | 6.30.1 |
| prompt_toolkit | 3.0.52 |
| crc32c | 2.7.1 |
| pyarrow | 21.0.0 |
| six | 1.17.0 |
| psutil | 7.1.0 |
| typing_extensions | 4.15.0 |
| fsspec | 2025.12.0 |
| charset-normalizer | 3.4.3 |
| patsy | 1.0.1 |
| debugpy | 1.8.17 |
| wcwidth | 0.2.14 |
| matplotlib | 3.10.6 |
| toolz | 1.1.0 |
| scikit-learn | 1.7.2 |
Copyable Markdown
| Package | Version | | ------------- | ------------- | | pandas | 2.2.2 | | scanpy | 1.11.4 | | plotnine | 0.15.0 | | liana | 1.7.1 (1.7.3) | | pycrosstalker | 2.1.6 | | scipy | 1.15.3 | | Dependency | Version | | ------------------ | --------------------- | | setuptools | 80.9.0 | | llvmlite | 0.45.0 | | pyparsing | 3.2.5 | | Jinja2 | 3.1.6 | | igraph | 1.0.0 | | xarray | 2025.12.0 | | numpy | 2.3.3 | | leidenalg | 0.11.0 | | PyYAML | 6.0.3 | | pycparser | 2.23 | | comm | 0.2.3 | | cloudpickle | 3.1.2 | | urllib3 | 2.5.0 | | dask | 2024.11.2 | | Pygments | 2.19.2 | | matplotlib-inline | 0.1.7 | | cffi | 2.0.0 | | texttable | 1.7.0 | | natsort | 8.4.0 | | jupyter_core | 5.8.1 | | certifi | 2025.8.3 (2025.08.03) | | executing | 2.2.1 | | plotly | 6.8.0 | | threadpoolctl | 3.6.0 | | pillow | 11.3.0 | | kiwisolver | 1.4.9 | | sankeyflow | 0.4.1 | | anndata | 0.12.2 | | mudata | 0.3.2 | | joblib | 1.5.2 | | packaging | 25.0 | | h5py | 3.14.0 | | pytz | 2025.2 | | decorator | 5.2.1 | | parso | 0.8.5 | | appnope | 0.1.4 | | legacy-api-wrap | 1.4.1 | | python-dateutil | 2.9.0.post0 | | stack_data | 0.6.3 | | adjustText | 1.3.0 | | docrep | 0.3.2 | | platformdirs | 4.4.0 | | attrs | 25.4.0 | | requests | 2.32.5 | | seaborn | 0.13.2 | | tornado | 6.5.2 | | jupyter_client | 8.6.3 | | idna | 3.10 | | ipython | 9.6.0 | | statsmodels | 0.14.5 | | pure_eval | 0.2.3 | | tqdm | 4.67.1 | | pyzmq | 27.1.0 | | MarkupSafe | 3.0.3 | | donfig | 0.8.1.post1 | | cycler | 0.12.1 | | session-info2 | 0.2.2 | | traitlets | 5.14.3 | | networkx | 3.5 | | asttokens | 3.0.0 | | gprofiler-official | 1.0.0 | | numcodecs | 0.16.3 | | numba | 0.62.0 | | jedi | 0.19.2 | | mizani | 0.14.2 | | zarr | 3.1.3 | | ipykernel | 6.30.1 | | prompt_toolkit | 3.0.52 | | crc32c | 2.7.1 | | pyarrow | 21.0.0 | | six | 1.17.0 | | psutil | 7.1.0 | | typing_extensions | 4.15.0 | | fsspec | 2025.12.0 | | charset-normalizer | 3.4.3 | | patsy | 1.0.1 | | debugpy | 1.8.17 | | wcwidth | 0.2.14 | | matplotlib | 3.10.6 | | toolz | 1.1.0 | | scikit-learn | 1.7.2 | | Component | Info | | --------- | -------------------------------------------------------------------------------- | | Python | 3.13.7 | packaged by conda-forge | (main, Sep 3 2025, 14:24:46) [Clang 19.1.7 ] | | OS | macOS-15.7.7-arm64-arm-64bit-Mach-O | | CPU | 8 logical CPU cores, arm | | GPU | No GPU found | | Updated | 2026-06-29 11:49 |
Load & Prep Data#
As a simple example, we will look at ~25k PBMCs from 8 pooled patient lupus samples, each before and after IFN-beta stimulation (Kang et al., 2018; GSE96583). Note that by focusing on PBMCs, for the purpose of this tutorial, we assume that coordinated events occur among them.
This dataset is downloaded from a link on Figshare; preprocessed for pertpy.
# load data as from CCC chapter
adata = li.testing.datasets.kang_2018()
Showcase anndata object#
adata.obs.head()
| nCount_RNA | nFeature_RNA | tsne1 | tsne2 | condition | cluster | cell_type | patient | nCount_SCT | nFeature_SCT | integrated_snn_res.0.4 | seurat_clusters | sample | cell_abbr | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | ||||||||||||||
| AAACATACATTTCC-1 | 3017.0 | 877 | -27.640373 | 14.966629 | ctrl | 9 | CD14+ Monocytes | patient_1016 | 1704.0 | 711 | 1 | 1 | ctrl&1016 | CD14 |
| AAACATACCAGAAA-1 | 2481.0 | 713 | -27.493646 | 28.924885 | ctrl | 9 | CD14+ Monocytes | patient_1256 | 1614.0 | 662 | 1 | 1 | ctrl&1256 | CD14 |
| AAACATACCATGCA-1 | 703.0 | 337 | -10.468194 | -5.984389 | ctrl | 3 | CD4 T cells | patient_1488 | 908.0 | 337 | 6 | 6 | ctrl&1488 | CD4T |
| AAACATACCTCGCT-1 | 3420.0 | 850 | -24.367997 | 20.429285 | ctrl | 9 | CD14+ Monocytes | patient_1256 | 1738.0 | 653 | 1 | 1 | ctrl&1256 | CD14 |
| AAACATACCTGGTA-1 | 3158.0 | 1111 | 27.952170 | 24.159738 | ctrl | 4 | Dendritic cells | patient_1039 | 1857.0 | 928 | 12 | 12 | ctrl&1039 | DCs |
adata.obs["cell_type"].cat.categories
Index(['CD4 T cells', 'CD14+ Monocytes', 'B cells', 'NK cells', 'CD8 T cells',
'FCGR3A+ Monocytes', 'Dendritic cells', 'Megakaryocytes'],
dtype='object')
sample_key = 'sample'
condition_key = 'condition'
groupby = 'cell_type'
Basic QC#
Note that this data has been largely pre-processed & annotated, we refer the user to the Quality Control and other relevant chapters from the best-practices book for information about pre-processing and annotation steps.
# filter cells and genes
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
# log1p normalize the data
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
In addition to the basic QC steps, one needs to ensure that the cell groups on which they run the analysis are well defined, and stable across samples.
Show pre-computed UMAP#
adata
AnnData object with n_obs × n_vars = 24562 × 15701
obs: 'nCount_RNA', 'nFeature_RNA', 'tsne1', 'tsne2', 'condition', 'cluster', 'cell_type', 'patient', 'nCount_SCT', 'nFeature_SCT', 'integrated_snn_res.0.4', 'seurat_clusters', 'sample', 'cell_abbr', 'n_genes'
var: 'name', 'n_cells'
uns: 'log1p'
obsm: 'X_pca', 'X_umap'
layers: 'counts'
sc.pl.umap(adata, color=[condition_key, groupby], frameon=False)
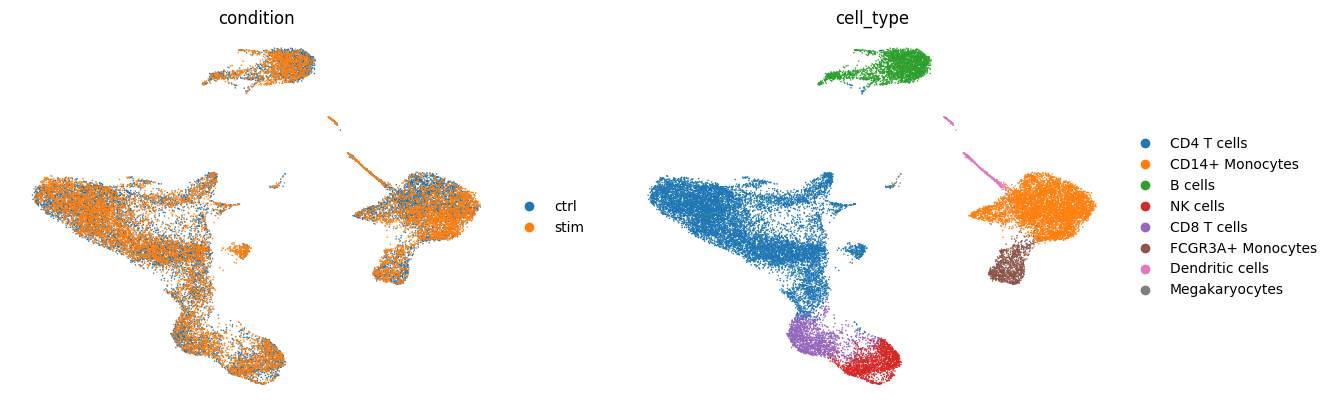
Ligand-Receptor Inference by Sample#
To compare the effects of stimulation on cell-cell communication, we will first perform ligand-receptor inference using the methods implemented in the liana framework, as example of scseqcomm.
li.mt.scseqcomm.by_sample(
adata,
groupby=groupby,
resource_name='consensus', # NOTE: uses human gene symbols!
sample_key=condition_key, # sample key by which we which to loop
use_raw=False,
verbose=True, # use 'full' to show all verbose information
n_perms=10, # exclude permutations for speed
return_all_lrs=False# return all LR values
)
Check results
In total, we obtained 1892 interactions for the control samples and 1987 for stimulated interactions. Now, we use CrossTalkeR for performing a graph-based differential cell-cell communication analysis
adata.uns["liana_res"]
| condition | ligand | ligand_cdf | ligand_complex | ligand_means | ligand_props | receptor | receptor_cdf | receptor_complex | receptor_means | receptor_props | source | target | inter_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ctrl | HLA-B | 1.000000 | HLA-B | 2.031854 | 0.984712 | CD3D | 1.000000 | CD3D | 0.622439 | 0.608993 | CD4 T cells | CD4 T cells | 1.000000 |
| 1 | ctrl | HLA-B | 1.000000 | HLA-B | 2.031854 | 0.984712 | KLRD1 | 1.000000 | KLRD1 | 0.333456 | 0.332922 | CD4 T cells | CD8 T cells | 1.000000 |
| 2 | ctrl | HLA-C | 1.000000 | HLA-C | 1.384611 | 0.912950 | CD8B | 1.000000 | CD8B | 0.262738 | 0.255240 | CD4 T cells | CD8 T cells | 1.000000 |
| 3 | ctrl | HLA-C | 1.000000 | HLA-C | 1.384611 | 0.912950 | CD8A | 1.000000 | CD8A | 0.388470 | 0.371147 | CD4 T cells | CD8 T cells | 1.000000 |
| 4 | ctrl | CD48 | 1.000000 | CD48 | 0.127942 | 0.164388 | CD2 | 1.000000 | CD2 | 0.765779 | 0.621455 | CD4 T cells | CD8 T cells | 1.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3874 | stim | CD47 | 0.911753 | CD47 | 0.066570 | 0.166667 | SIRPA | 0.327294 | SIRPA | 0.031316 | 0.110701 | Megakaryocytes | Dendritic cells | 0.327294 |
| 3875 | stim | CD47 | 1.000000 | CD47 | 0.213795 | 0.272807 | SIRPA | 0.327294 | SIRPA | 0.031316 | 0.110701 | CD4 T cells | Dendritic cells | 0.327294 |
| 3876 | stim | SIRPA | 0.327294 | SIRPA | 0.031316 | 0.110701 | CD47 | 1.000000 | CD47 | 0.447850 | 0.645570 | Dendritic cells | CD14+ Monocytes | 0.327294 |
| 3877 | stim | CD47 | 1.000000 | CD47 | 0.258852 | 0.288889 | SIRPA | 0.327294 | SIRPA | 0.031316 | 0.110701 | CD8 T cells | Dendritic cells | 0.327294 |
| 3878 | stim | CD47 | 1.000000 | CD47 | 0.408296 | 0.483146 | SIRPA | 0.327294 | SIRPA | 0.031316 | 0.110701 | B cells | Dendritic cells | 0.327294 |
3879 rows × 14 columns
adata = cttl.utils.from_liana(adata,
liana_key = "liana_res",
compute_means=True,pval_filter=False)
adata = cttl.analise_LR(adata,save=False)
Create a Differential Table
Calculating CCI Ranking
Calculating GCI Ranking
Network Analysis Done
Generating h5ad file with Analysed Results
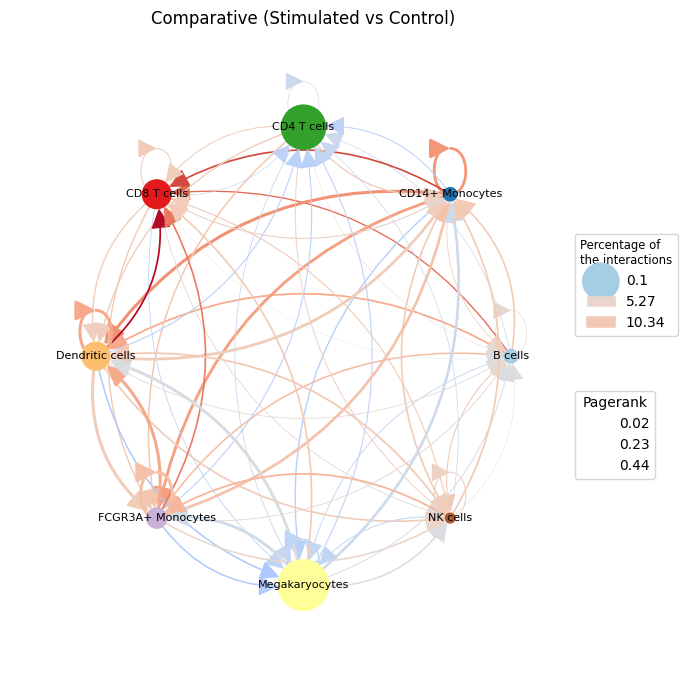
We visualize the main differences with plot_cci, which draws the comparative communication graph (stimulated vs. control):
Nodes are cell types, coloured by cell type. Node size encodes the magnitude of each cell type’s change in PageRank importance between conditions — larger nodes changed the most.
Edges are the differential signalling between cell types: red edges are stronger under stimulation, blue edges stronger under control; edge width scales with the size of the difference.
We pass the absolute differential PageRank as the node size (.abs()), since size reflects how much a cell type’s role changed; the direction of change is read from the edge colours and from the ranking bar plot further down.
ctpl.plot.plot_cci(graph=adata.uns['pycrosstalker']['results']["graphs"]["stim_x_ctrl"],
colors=adata.uns['pycrosstalker']['results']["colors"],
plt_name='Comparative (Stimulated vs Control)',
coords=adata.uns['pycrosstalker']['results']["coords"],
emax= None,
leg= False,
low= 0,
high= 0,
ignore_alpha= False,
log= False,
efactor= 2,
vfactor= 12,
# node size = magnitude of the differential PageRank (signed -> abs),
# otherwise cell types that drop in importance get a negative size and vanish
pg= adata.uns['pycrosstalker']['results']["rankings"]["stim_x_ctrl"]["Pagerank"].abs(),
figsize= (7, 7),
scale_factor= 2.0,
node_size=3.0,
font_size=8,
)
Beyond the graph view, pyCrossTalkeR tests which cell-cell pairs change significantly between conditions. The first test compares the number of interactions (the count of LR pairs) per cell-type pair using a Fisher/proportion test. The volcano plot below shows the fold-change vs. significance, highlighting pairs that gain or lose interactions under stimulation.
ctpl.plot_volcane(adata.uns['pycrosstalker']['results']['stats']['stim_x_ctrl'],
"fisher",
p_threshold=0.05,
fc_threshold=1, annot=True, title="Volcano Plot for Stimulated vs Control on Fisher Filtered Data")
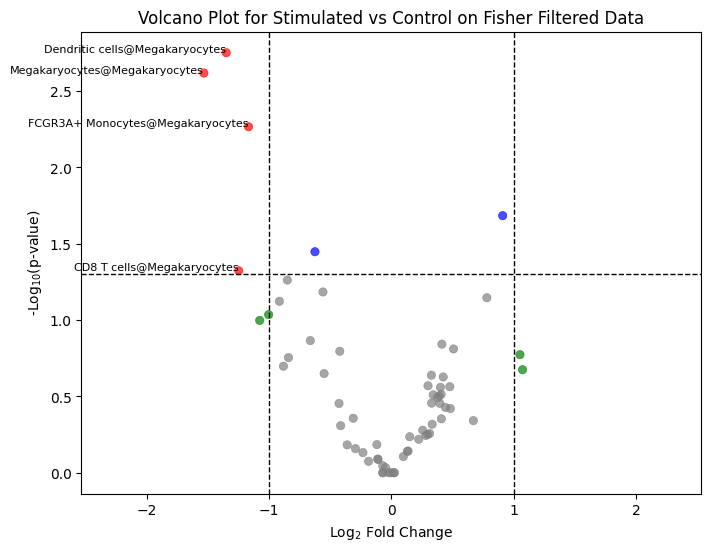
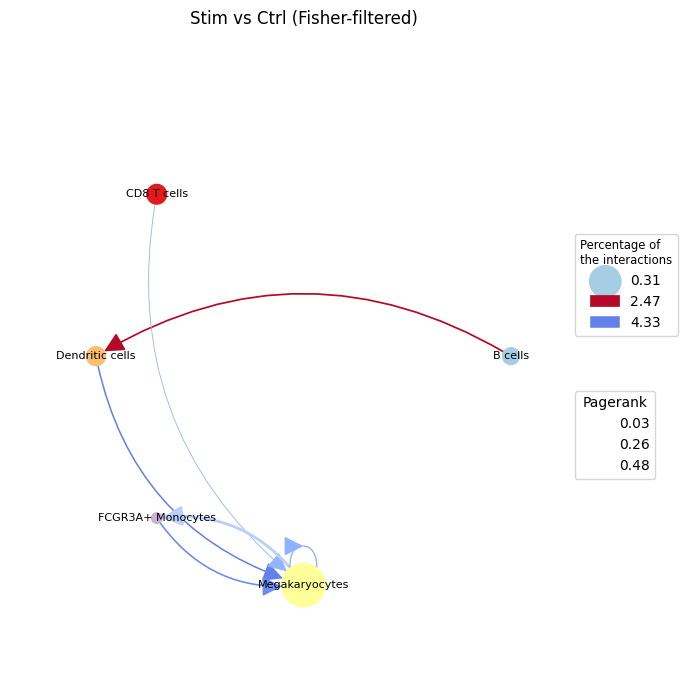
From the proportion test we see an increase in interactions from B cells to Dendritic cells under stimulation — consistent with the IFN-β response also highlighted in the liana-cell2cell notebook. Restricting the comparative graph to these significantly-changed pairs (the Fisher-filtered graph) gives a cleaner view of where communication is rewired:
ctpl.plot.plot_cci(graph=adata.uns['pycrosstalker']['results']["graphs"]["stim_x_ctrl_filtered"],
colors=adata.uns['pycrosstalker']['results']["colors"],
plt_name='Stim vs Ctrl (Fisher-filtered)',
coords=adata.uns['pycrosstalker']['results']["coords"],
emax= None,
leg= False,
low= 0,
high= 0,
ignore_alpha= False,
log= False,
efactor= 2,
vfactor= 12,
# node size = magnitude of the differential PageRank (signed -> abs)
pg= adata.uns['pycrosstalker']['results']["rankings"]["stim_x_ctrl_filtered"]["Pagerank"].abs(),
figsize= (7, 7),
scale_factor= 2.0,
node_size=2.0,
font_size=8,
)
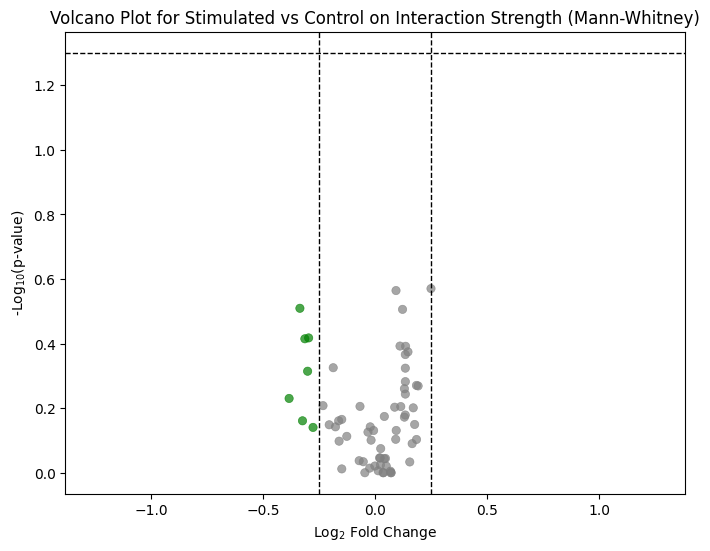
The second test complements this by comparing the strength of interactions (the LR scores) rather than their count, using a Mann-Whitney U test. This volcano plot flags cell-type pairs whose signalling intensity — not just the number of active LR pairs — shifts between conditions.
ctpl.plot_volcane(adata.uns['pycrosstalker']['results']['stats']['stim_x_ctrl:MannU'],
"mannwhitneyu",
p_threshold=0.05,
fc_threshold=0.25, annot=True, title="Volcano Plot for Stimulated vs Control on Interaction Strength (Mann-Whitney)")
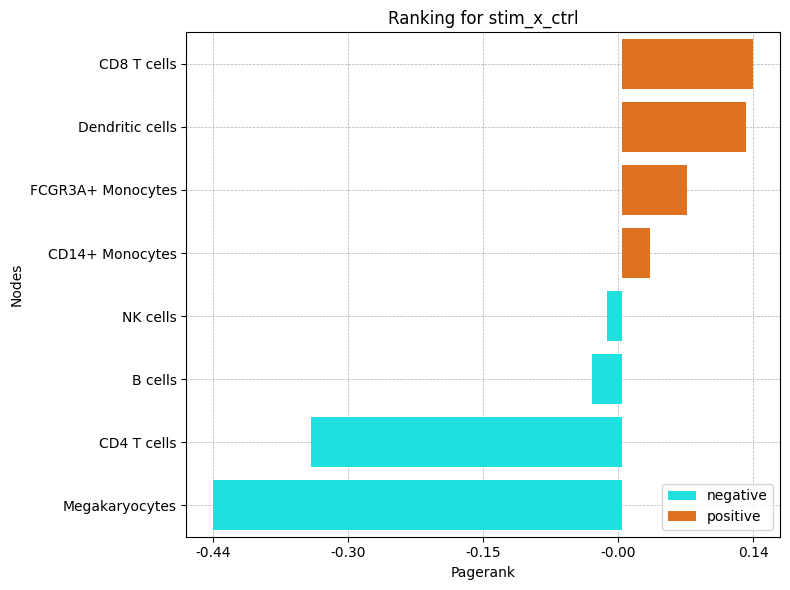
The bar plot ranks cell types by their differential PageRank: positive values gain communication importance under stimulation, negative values lose it. This is the signed quantity whose magnitude sized the nodes in the graph above.
The clustermap shows the same Fisher-filtered differential graph as a sender × receiver matrix, clustering cell types by their changed signalling so that coordinated shifts (e.g. shared senders or receivers) become apparent.
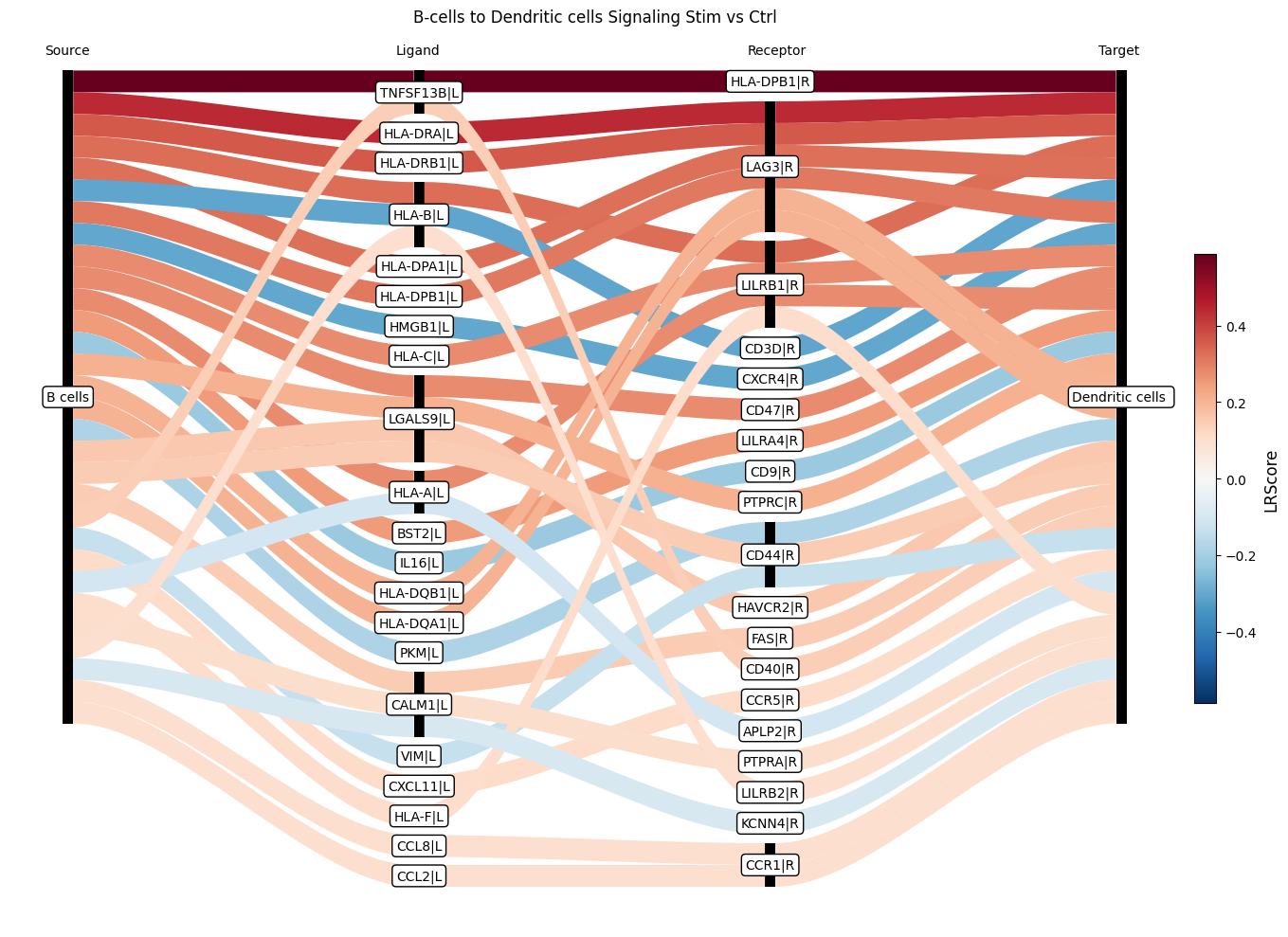
Finally, the Sankey plot zooms into a single sender→receiver pair (here B cells → Dendritic cells) and breaks the change down to the level of individual ligand-receptor pairs, showing which interactions drive the differential signal between conditions.
ctpl.plot_bar_rankings(adata, "stim_x_ctrl", "Pagerank")
This notebook covered the core comparative workflow: per-condition LR inference with liana, graph construction and ranking with pyCrossTalkeR, and reading out condition-driving cell types and interactions. The full range of downstream analyses — including cell-gene (CGI) networks and PCA of the rankings — is documented in the pyCrossTalkeR tutorial.
ctpl.plot_sankey(
adata.uns['pycrosstalker']['results']['tables']['stim_x_ctrl'],
ligand_cluster = ["B cells"],
receptor_cluster = ["Dendritic cells"],
plt_name = "B-cells to Dendritic cells Signaling Stim vs Ctrl",
threshold = 30)
Outlook & Further Analysis#
There are different ways to explore these results downstream of the pyCrossTalker, these can be further performed using pyCrossTalkeR Tutorial.